ARA-C01 Guaranteed Passing | ARA-C01 Actual Braindumps
Wiki Article
P.S. Free 2026 Snowflake ARA-C01 dumps are available on Google Drive shared by Prep4cram: https://drive.google.com/open?id=1Ed-8tdQw6hyGV8twpzZ_Kcs0zZUiQPW6
Although our ARA-C01 exam braindumps have been recognised as a famous and popular brand in this field, but we still can be better by our efforts. In the future, our ARA-C01 study materials will become the top selling products. Although we come across some technical questions of our ARA-C01 learning guide during development process, we still never give up to developing our ARA-C01 practice engine to be the best in every detail.
Snowflake ARA-C01 Exam is a timed, multiple-choice exam that contains 75 questions. Candidates have 120 minutes to complete the exam, and they must score at least 70% to pass. ARA-C01 exam is available in English, Japanese, and Spanish, and can be taken online from anywhere in the world. Successful candidates will receive a digital badge and certificate, which they can use to showcase their expertise in Snowflake architecture.
>> ARA-C01 Guaranteed Passing <<
ARA-C01 Actual Braindumps | New ARA-C01 Test Objectives
When we choose the employment work, you will meet a bottleneck, how to let a company to choose you to be a part of him? We would say ability, so how does that show up? There seems to be only one quantifiable standard to help us get a more competitive job, which is to get the test ARA-C01certification and obtain a qualification. If you want to have a good employment platform, then take office at the same time there is a great place to find that we have to pay attention to the importance of qualification examination.
Snowflake SnowPro Advanced Architect Certification Sample Questions (Q202-Q207):
NEW QUESTION # 202
Which of the following are characteristics of Snowflake's parameter hierarchy?
- A. Session parameters override virtual warehouse parameters.
- B. Schema parameters override account parameters.
- C. Virtual warehouse parameters override user parameters.
- D. Table parameters override virtual warehouse parameters.
Answer: B
Explanation:
Explanation
This is the correct answer because it reflects the characteristics of Snowflake's parameter hierarchy.
Snowflake provides three types of parameters that can be set for an account: account parameters, session parameters, and object parameters. All parameters have default values, which can be set and then overridden at different levels depending on the parameter type. The following diagram illustrates the hierarchical relationship between the different parameter types and how individual parameters can be overridden at each level1:
As shown in the diagram, schema parameters are a type of object parameters that can be set for schemas.
Schema parameters can override the account parameters that are set at the account level. For example, the LOG_LEVEL parameter can be set at the account level to control the logging level for all objects in the account, but it can also be overridden at the schema level to control the logging level for specific stored procedures and UDFs in that schema2.
The other options listed are not correct because they do not reflect the characteristics of Snowflake's parameter hierarchy. Session parameters do not override virtual warehouse parameters, because virtual warehouse parameters are a type of session parameters that can be set for virtual warehouses. Virtual warehouse parameters do not override user parameters, because user parameters are a type of session parameters that can be set for users. Table parameters do not override virtual warehouse parameters, because table parameters are a type of object parameters that can be set for tables, and object parameters do not affect session parameters1.
References:
* Snowflake Documentation: Parameters
* Snowflake Documentation: Setting Log Level
NEW QUESTION # 203
Which system functions does Snowflake provide to monitor clustering information within a table (Choose two.)
- A. SYSTEM$CLUSTERING_KEYS
- B. SYSTEM$CLUSTERING_USAGE
- C. SYSTEM$CLUSTERING_INFORMATION
- D. SYSTEM$CLUSTERING_PERCENT
- E. SYSTEM$CLUSTERING_DEPTH
Answer: C,E
Explanation:
According to the Snowflake documentation, these two system functions are provided by Snowflake to monitor clustering information within a table. A system function is a type of function that allows executing actions or returning information about the system. A clustering key is a feature that allows organizing data across micro-partitions based on one or more columns in the table. Clustering can improve query performance by reducing the number of files to scan.
* SYSTEM$CLUSTERING_INFORMATION is a system function that returns clustering information, including average clustering depth, for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns a JSON string
* with the clustering information. The clustering information includes the cluster by keys, the total partition count, the total constant partition count, the average overlaps, and the average depth1.
* SYSTEM$CLUSTERING_DEPTH is a system function that returns the clustering depth for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns an integer value with the clustering depth. The clustering depth is the maximum number of overlapping micro-partitions for any micro-partition in the table. A lower clustering depth indicates a better clustering2.
References:
* SYSTEM$CLUSTERING_INFORMATION | Snowflake Documentation
* SYSTEM$CLUSTERING_DEPTH | Snowflake Documentation
NEW QUESTION # 204
An Architect has been asked to clone schema STAGING as it looked one week ago, Tuesday June 1st at 8:00 AM, to recover some objects.
The STAGING schema has 50 days of retention.
The Architect runs the following statement:
CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-06-01 08:00:00'); The Architect receives the following error: Time travel data is not available for schema STAGING. The requested time is either beyond the allowed time travel period or before the object creation time.
The Architect then checks the schema history and sees the following:
CREATED_ON|NAME|DROPPED_ON
2021-06-02 23:00:00 | STAGING | NULL
2021-05-01 10:00:00 | STAGING | 2021-06-02 23:00:00
How can cloning the STAGING schema be achieved?
- A. Modify the statement: CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-05-01 10:00:00');
- B. Cloning cannot be accomplished because the STAGING schema version was not active during the proposed Time Travel time period.
- C. Undrop the STAGING schema and then rerun the CLONE statement.
- D. Rename the STAGING schema and perform an UNDROP to retrieve the previous STAGING schema version, then run the CLONE statement.
Answer: D
Explanation:
The error message indicates that the schema STAGING does not have time travel data available for the requested timestamp, because the current version of the schema was created on 2021-06-02 23:00:00, which is after the timestamp of 2021-06-01 08:00:00. Therefore, the CLONE statement cannot access the historical data of the schema at that point in time.
Option A is incorrect, because undropping the STAGING schema will not restore the previous version of the schema that was active on 2021-06-01 08:00:00. Instead, it will create a new version of the schema with the same name and no data or objects.
Option B is incorrect, because modifying the timestamp to 2021-05-01 10:00:00 will not clone the schema as it looked one week ago, but as it looked when it was first created. This may not reflect the desired state of the schema and its objects.
Option C is correct, because renaming the STAGING schema and performing an UNDROP to retrieve the previous STAGING schema version will restore the schema that was dropped on 2021-06-02 23:00:00. This schema has time travel data available for the requested timestamp of 2021-06-01 08:00:00, and can be cloned using the CLONE statement.
Option D is incorrect, because cloning can be accomplished by using the UNDROP command to access the previous version of the schema that was active during the proposed time travel period.
NEW QUESTION # 205
A company's daily Snowflake workload consists of a huge number of concurrent queries triggered between
9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the company's Architect implement to enhance the performance of this workload?
(Choose two.)
- A. Enable a multi-clustered virtual warehouse in maximized mode during the workload duration.
- B. Set the connection timeout to a higher value than its default.
- C. Reduce the amount of data that is being processed through this workload.
- D. Increase the size of the virtual warehouse to size X-Large.
- E. Set the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level.
Answer: A,E
Explanation:
These two configuration options can enhance the performance of the workload that consists of a huge number of concurrent queries that are smaller and faster.
* Enabling a multi-clustered virtual warehouse in maximized mode allows the warehouse to scale out automatically by adding more clusters as soon as the current cluster is fully loaded, regardless of the number of queries in the queue. This can improve the concurrency and throughput of the workload by minimizing or preventing queuing. The maximized mode is suitable for workloads that require high performance and low latency, and are less sensitive to credit consumption1.
* Setting the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level allows the warehouse to run more queries concurrently on each cluster. This can
* improve the utilization and efficiency of the warehouse resources, especially for smaller and faster queries that do not require a lot of processing power. The MAX_CONCURRENCY_LEVEL parameter can be set when creating or modifying a warehouse, and it can be changed at any time2.
References:
* Snowflake Documentation: Scaling Policy for Multi-cluster Warehouses
* Snowflake Documentation: MAX_CONCURRENCY_LEVEL
NEW QUESTION # 206
Please select the correct hierarchy from below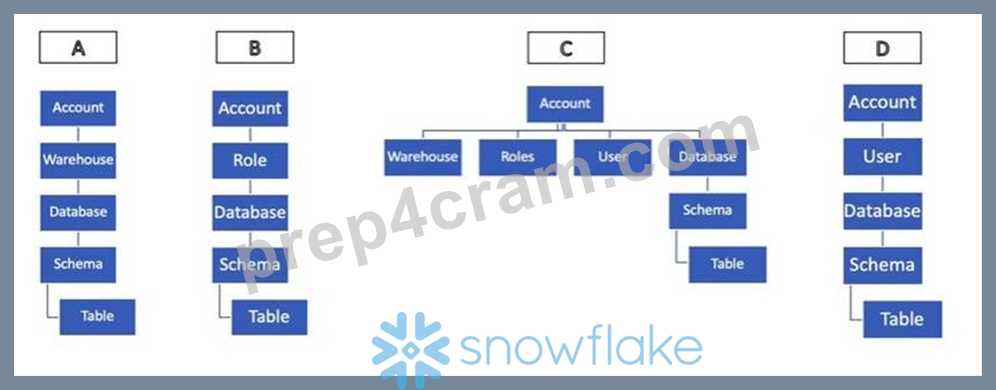
- A. Option A
- B. Option C
- C. Option D
- D. Option B
Answer: B
NEW QUESTION # 207
......
By analyzing the syllabus and new trend, our ARA-C01 practice engine is totally in line with this exam for your reference. So grapple with this chance, our ARA-C01 learning materials will not let you down. With our ARA-C01 Study Guide, not only that you can pass you exam easily and smoothly, but also you can have a wonderful study experience based on the diversed versions of our ARA-C01 training prep.
ARA-C01 Actual Braindumps: https://www.prep4cram.com/ARA-C01_exam-questions.html
- 100% Pass Quiz Snowflake - ARA-C01 - SnowPro Advanced Architect Certification Fantastic Guaranteed Passing ???? Search for ➠ ARA-C01 ???? and obtain a free download on ➠ www.prepawaypdf.com ???? ????ARA-C01 Top Dumps
- Free PDF 2026 Perfect Snowflake ARA-C01: SnowPro Advanced Architect Certification Guaranteed Passing ???? Immediately open ▶ www.pdfvce.com ◀ and search for ➽ ARA-C01 ???? to obtain a free download ⚒Latest Braindumps ARA-C01 Ppt
- Trustable Snowflake - ARA-C01 Guaranteed Passing ???? Open website ➽ www.prepawaypdf.com ???? and search for ➠ ARA-C01 ???? for free download ????ARA-C01 Exam Introduction
- Reliable ARA-C01 Guaranteed Passing - Pass ARA-C01 Once - Well-Prepared ARA-C01 Actual Braindumps ???? Search for 《 ARA-C01 》 and download it for free on ➠ www.pdfvce.com ???? website ????ARA-C01 New Braindumps Book
- 100% Pass Quiz Snowflake - ARA-C01 - SnowPro Advanced Architect Certification Fantastic Guaranteed Passing ???? Go to website ➤ www.examdiscuss.com ⮘ open and search for ➡ ARA-C01 ️⬅️ to download for free ????Valid Dumps ARA-C01 Ppt
- Pass Guaranteed Quiz 2026 Snowflake ARA-C01 – High Pass-Rate Guaranteed Passing ???? Open ⏩ www.pdfvce.com ⏪ and search for ✔ ARA-C01 ️✔️ to download exam materials for free ????Exam ARA-C01 Book
- ARA-C01 Accurate Study Material ???? ARA-C01 Certification Test Questions ???? Exam ARA-C01 Book ???? Go to website ⮆ www.easy4engine.com ⮄ open and search for [ ARA-C01 ] to download for free ????Valid ARA-C01 Test Cost
- 100% Pass Snowflake - Reliable ARA-C01 Guaranteed Passing ???? Go to website ➡ www.pdfvce.com ️⬅️ open and search for 【 ARA-C01 】 to download for free ????Printable ARA-C01 PDF
- Exam ARA-C01 Prep ???? Positive ARA-C01 Feedback ???? Printable ARA-C01 PDF ???? Search for ➡ ARA-C01 ️⬅️ and download it for free on ⇛ www.pdfdumps.com ⇚ website ????Positive ARA-C01 Feedback
- Free PDF 2026 Perfect Snowflake ARA-C01: SnowPro Advanced Architect Certification Guaranteed Passing ???? Download 「 ARA-C01 」 for free by simply entering “ www.pdfvce.com ” website ????Valid Dumps ARA-C01 Ppt
- ARA-C01 Top Dumps ???? ARA-C01 Study Center ???? ARA-C01 Accurate Study Material ???? Search for 【 ARA-C01 】 and easily obtain a free download on 「 www.examdiscuss.com 」 ????Valid Dumps ARA-C01 Ppt
- bookmark-group.com, adamfrda970246.blog-gold.com, owainqvsf170138.prublogger.com, onlybookmarkings.com, minibookmarks.com, heidilijv127907.tdlwiki.com, bookmarkextent.com, safaeefs001244.blogspothub.com, saadmids420635.wikifrontier.com, chiarafxvc662451.blogsvila.com, Disposable vapes
2026 Latest Prep4cram ARA-C01 PDF Dumps and ARA-C01 Exam Engine Free Share: https://drive.google.com/open?id=1Ed-8tdQw6hyGV8twpzZ_Kcs0zZUiQPW6
Report this wiki page